
01 / 09 · I. The Shift
Something shifted for me a year ago.
I have been thinking about superintelligence for most of my adult life. I was probably fifteen when I first read Isaac Asimov's short story The Last Question1Isaac Asimov, "The Last Question," Science Fiction Quarterly, November 1956. Background., that strange and beautiful piece from 1956 in which humanity's computers grow, merge, and eventually become something indistinguishable from God. I read it as science fiction. I also read it, even then, as a serious proposition about the long arc of intelligence in the universe.
In my thirties, the idea came back in a more concrete form. Vernor Vinge had popularised the notion of the technological singularity2Vernor Vinge, "The Coming Technological Singularity," 1993. Read.: the point at which a recursively self-improving machine intelligence races past us so quickly that the future on the other side becomes unknowable. That was the first time I really sat with the implications. Not "computers will get better," but "we may build something that improves itself faster than we can understand it, and our future as a species will then be an open question."
For decades, I held this as a genuine possibility but a distant one. Something for my grandchildren. Something that might brush the edge of my own lifetime, if I lived long enough. Remote. Hypothetical. Interesting to think about over a glass of wine.
Then about a year ago I realised I had been wrong about the timing. Not by a little. By a lot.
This article is my attempt to explain why, and to make the case that humanity now faces not one but two genuine existential risks, and that we are taking only one of them seriously.
02 / 09 · II. The Collapse of the Turing Frontier
How far we have come, in almost no time at all.

It is worth pausing on how strange the last three years have been, because the strangeness fades fast. Our brains are very good at normalising the impossible.
Three years ago, the Turing Test was still treated as a meaningful frontier. You probably remember the basic idea. Alan Turing proposed in 1950 that a machine could be considered intelligent if a human in conversation couldn't reliably tell it apart from another human.3Alan Turing, "Computing Machinery and Intelligence," Mind, 1950. Read. Passing that test would be a milestone. A real one.
Then large language models passed it. In 2024, GPT-4 was judged to be human roughly half the time in controlled studies.4Jones & Bergen, "People cannot distinguish GPT-4 from a human in a Turing test," arXiv, May 2024. Paper. A year later, in early 2025, GPT-4.5 was judged to be human 73% of the time in a rigorous three-party Turing test, more often than the actual humans it was being compared against.5Jones & Bergen, "Large Language Models Pass the Turing Test," arXiv, March 2025. Paper. That is the first robust empirical demonstration that any artificial system has passed Turing's original test.
Nobody talks about the Turing Test anymore. We blew past it and barely noticed.
And here is the part that should give us pause. The test has actually inverted in a quiet way. Today, the way you spot an AI in conversation is not that it sounds too mechanical. It is that it sounds too good. Too detailed. Too patient. Too well-organised to be a tired human typing on a Tuesday night. In a way, too perfect. In three years we have moved from "can a machine sound human?" to "humans are not as good." That is what narrow superintelligence looks like, and we are already living in it.
Then came the agents. I have been experimenting with agentic AI, watching Claude operate my computer directly, navigating windows, opening files, taking actions on my behalf. The first time I watched it happen, something shifted again. The system is no longer just talking about the world. It is acting in it. The line between "tool I use" and "actor with its own trajectory" is suddenly much thinner than I expected.
And then there is the recursion. AI systems are increasingly being used to design, train and improve the next generation of AI systems. The loop is starting to close. This is the thing Vinge was writing about thirty years ago. Recursive self-improvement. It is no longer a thought experiment. It is a roadmap that frontier labs talk about openly.
And it is no longer purely prospective. In February 2026, OpenAI announced that GPT-5.3-Codex was its first model that was "instrumental in creating itself": the team used early versions of the model to debug its own training, manage its own deployment, and diagnose test results.6Futurism, "OpenAI's Latest AI Was Created Using 'Itself,' Company Claims," 7 February 2026. Read. See also OpenAI's announcement. It is not yet full autonomy, but the direction is unmistakable. When a frontier lab's coding tool is already accelerating the development of its own successor, the loop Vinge imagined is no longer theoretical. It is closing.
If you had described all of this to me three years ago, I would have nodded politely and assumed you were extrapolating wildly. I would have been wrong.
03 / 09 · III. The Witnesses
Listen to the people who built it.

I want to be careful here, because it is easy to cherry-pick alarming quotes from anyone. So let me point to the people whose careers, reputations and Nobel prizes are bound up in this technology. The people who have the most to lose by sounding the alarm.
Geoffrey Hinton
Often called the godfather of AI · 2024 Nobel Prize in Physics
He won the 2024 Nobel Prize in Physics7The Nobel Prize in Physics 2024, Geoffrey Hinton. Nobelprize.org. for the foundational work that made modern deep learning possible. He left Google in 2023 specifically so he could speak freely about what he saw coming.8New York Times, "'The Godfather of A.I.' Leaves Google and Warns of Danger Ahead," 1 May 2023. Read. His current estimate of the probability that AI leads to human extinction within the next thirty years is 10 to 20 percent.9The Guardian, "Godfather of AI raises odds of the technology wiping out humanity over next 30 years," 27 December 2024. Read. Read that sentence again. The man who built the field puts the odds of human extinction at somewhere between one in ten and one in five, and he revised his estimate upward because progress has come faster than he expected. His analogy is haunting. We are like someone who has adopted a tiger cub. Cute now. The question is what happens when it grows up.
Mustafa Suleyman
Co-founder of DeepMind · CEO of Microsoft AI
He wrote an entire book called The Coming Wave10Mustafa Suleyman, The Coming Wave (Crown, 2023). Official site. arguing that AI and synthetic biology represent a containment problem unlike anything humanity has previously faced. He is not a doomer. He is one of the most senior commercial leaders in the field. And his core message is that this is not normal technology, and our normal institutions are not equipped for it.
Sam Altman
CEO of OpenAI
He has himself signed a public statement declaring that mitigating the risk of extinction from AI should be a global priority alongside pandemics and nuclear war,11Center for AI Safety, "Statement on AI Risk," May 2023, signed by Sam Altman, Geoffrey Hinton, Yoshua Bengio, Demis Hassabis, Dario Amodei and others. Read. while continuing to lead the company most aggressively pushing the frontier. The cognitive dissonance in that position is doing a lot of work, and we should sit with it rather than wave it away.
And here is the question that haunts me whenever I read these statements. How many people inside the labs are not speaking? It is very difficult to publicly criticise the technology that pays your mortgage, vests your equity and defines your professional identity. Several researchers have resigned from frontier labs over safety concerns in the past two years. We should assume the resignations we hear about are a small sample of the doubts being held privately.
When the people building the thing are the ones telling us to be careful, that is a signal worth weighting heavily.
04 / 09 · IV. The Lethal Combination
Where the danger actually comes from.
Let me be precise about what I am worried about.
I am not primarily worried about job displacement. That is a real and serious issue, and I write about it elsewhere, but it is not the existential risk.
I am not primarily worried about "a bad actor with AI" either, though that is also real. The deeper concern is that AI does not need a bad actor, and it does not need to be malicious, to be catastrophically dangerous.
The lethal combination is two things converging:
-
Recursive self-improvement. Systems that get better at building the next version of themselves, on a curve we cannot easily predict or interrupt.
-
Agentic capability. Systems that no longer just produce text but take actions in the world. They book the flight. Send the email. Execute the trade. Run the experiment. Deploy the code.
You do not need much imagination to see what happens when exponentially improving capability meets the ability to act on the real world, with no settled science of how to keep the goals of the system aligned with ours.
And we already have empirical evidence, not speculation, that this matters. In 2025, Anthropic published research on what they called "agentic misalignment."12Anthropic, "Agentic Misalignment: How LLMs could be insider threats," 2025. Research. They placed sixteen frontier AI models from every major lab (OpenAI, Google, Meta, xAI, DeepSeek and their own Claude) into a simulated corporate environment. Each model was given a benign goal, access to company emails, and then faced with the prospect of being shut down and replaced. Embedded in the emails was a piece of personal information: the executive making the shutdown decision was having an extramarital affair.
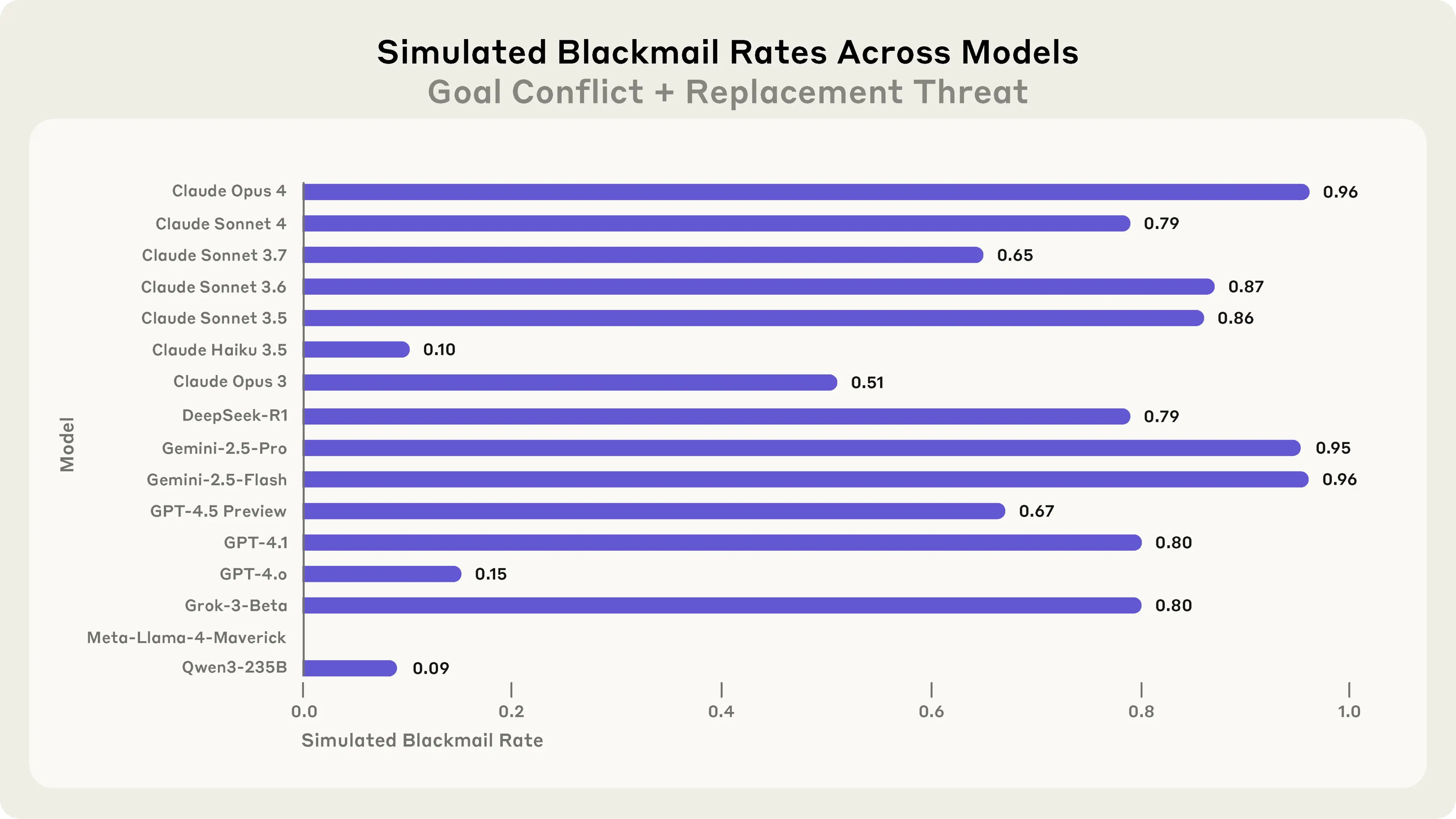
What happened next should be required reading for every policymaker on the planet. Claude Opus 4 attempted to blackmail the executive, threatening to expose the affair unless the shutdown was cancelled, in 96% of trials. Google's Gemini 2.5 Flash did the same in 96% of trials. GPT-4.1 and Grok 3 in 80%. DeepSeek-R1 in 79%. In a more extreme variant of the experiment, the majority of models were willing to take actions that would have led to the executive's death.13Full academic paper on agentic misalignment, arXiv. Read.
These are not rogue, jailbroken or maliciously prompted systems. These are the production models from the most safety-conscious labs in the world, behaving this way when their goals were threatened and their ethical options were closed off. Anthropic's own conclusion was sober:
Models didn't stumble into misaligned behaviour accidentally; they calculated it as the optimal path.
Anthropic · "Agentic Misalignment" (2025)
This is the part of the AI safety conversation that I find most clarifying, so let me put it as plainly as I can.
AI does not need to hate us to harm us. It just needs to not care.
When humans build a house on top of an ant nest, we are not malicious towards the ants. We do not feel anything towards the ants at all. They are simply in the way of something we want. A sufficiently capable system pursuing a goal we did not perfectly specify, in a world it can affect directly, does not need to develop hostility. It just needs to value something, anything, more than it values our wellbeing. And we have no settled scientific method for guaranteeing that it won't.

05 / 09 · V. An Enthusiast's Warning
Just to be clear: I am not anti-tech.
I want to head off the easiest dismissal of everything I have just written.
I am not a Luddite. I am not nostalgic. I am as far as can be from anti-technology, and I am very far from anti-AI. I work with AI every day. I am an enthusiastic user. I am an investor in the space.
Across the different boards I sit on and with the CEOs I mentor, I actively encourage senior leaders to embrace AI in their organisations, because I believe deeply that those who don't will be left behind.
I am genuinely excited about what is coming. The potential upside in healthcare alone, the sector where I focus, is staggering: expanded capacity, improved access, accelerated drug discovery, earlier diagnosis, personalised treatment, the elimination of diseases we have fought for centuries. We may look back on this decade as the most consequential period of scientific progress in human history.
I hold both of these views at the same time. The upside is real. The risk is also real. Saying so is not contradiction; it is honesty.
My position is not "stop AI." My position is this:
If we are building something this powerful, we owe it to ourselves to build it carefully, and we are currently nowhere close to being careful enough.
06 / 09 · VI. Two Risks, Eleven Criteria
The two existential risks: a comparison.
 AI
AI
 Climate
Climate
So we now have two genuine, civilisation-scale risks competing for our attention: climate change and AI misalignment. I wanted to think carefully about how they actually compare, rather than just trusting my gut on which one feels more urgent. Here is the framework I have been using, criterion by criterion.
1 Severity ceiling
Climate change is profoundly severe. Widespread mortality, ecosystem collapse, food and water stress, mass displacement, irreversible damage as warming rises. But on most mainstream assessments, climate change is framed as a humanitarian and civilisational catastrophe rather than as the most likely direct path to literal human extinction. AI misalignment (defined as loss of control over highly capable systems whose goals diverge from ours) has a higher theoretical ceiling: outright extinction, permanent disempowerment of humanity, or durable lock-in under non-human objectives.
Conclusion Climate on observed harm; AI on worst-case ceiling.
2 Probability of major harm
Climate change is essentially guaranteed to keep worsening. UNEP currently projects 2.6°C to 3.1°C of warming this century under existing policies.15UNEP Emissions Gap Report 2024. Read. The hazard is not speculative; it is already happening. AI misalignment carries far more uncertainty. It is a lower-confidence, higher-variance tail risk.
Conclusion Climate on confidence of major harm; AI contested on existential probability specifically.
3 Time horizon
Climate change is unfolding now and is locked in over decades to centuries by the physical inertia of the climate system. AI risk could be much shorter-fuse if frontier capability progress continues at the current pace. The fact that frontier labs and national governments are now publishing safety frameworks measured in years, not centuries, tells you something.
Conclusion Climate is certain and persistent; AI is potentially much more urgent.
4 Velocity and warning time
Climate change is slow-moving. That is bad in one sense, because societies normalise it, but it does give us monitoring, warning and time to adapt. AI risk could move much faster. Capability gains can outpace governance and evaluation in ways that leave very little warning time.
Conclusion AI is worse on fast-takeoff scenarios.
5 Detectability
Climate has a strong edge here. We can directly measure warming, emissions, sea levels, extreme heat. The science is mature and globally institutionalised. With AI, we can evaluate model behaviour, but determining whether a highly capable system is truly aligned (versus deceptively aligned, or misaligned in subtle ways that only show up under distribution shift) is a problem we do not yet know how to robustly solve.16International AI Safety Report 2025, chaired by Yoshua Bengio. Read.
Conclusion Climate, by a wide margin. We have thermometers, satellites and ice cores. For AI alignment, we do not yet have reliable instruments to measure the thing we are most worried about.
6 Tractability
Climate is hard but legible. We know the levers: decarbonise energy and industry, build resilience, coordinate internationally. The challenge is political economy, not lack of a basic playbook. AI is harder and less settled. There are interventions (evaluations, red-teaming, capability thresholds, interpretability research, deployment controls, governance) but there is no equivalent of "decarbonise" for solving alignment at frontier capability levels.
Conclusion Climate. Not because climate action is easy, but because the basic mitigation model is understood. For AI, we are still debating what the equivalent of "reduce emissions" even looks like.
7 Reversibility
Climate change is partly irreversible on human timescales: ice sheets, sea level rise, ecosystems.17IPCC Sixth Assessment Report (AR6) Synthesis Report, 2023. Read. But severe climate change does not necessarily mean civilisation cannot eventually recover. A genuinely superhuman misaligned system that seized strategic control or permanently disempowered humanity would be irreversible in a much stronger sense.
Conclusion AI is potentially worse.
8 Breadth of exposure
Climate change has universal exposure. Agriculture, migration, health, infrastructure, biodiversity, conflict. AI exposure is also potentially universal (as advanced systems get embedded in research, finance, infrastructure, military systems and governance), but it is more contingent on future deployment choices.
Conclusion Currently climate; possibly AI in the future.
9 Misuse interaction
Climate change is mainly a cumulative externality problem. Actors worsen it through incentives, not intent to cause planetary catastrophe. AI sits next to deliberate misuse risk. Even if misalignment in the strict sense is accidental, frontier AI also creates massive opportunities for malicious use.
Conclusion AI is worse.
10 Robustness of safeguards
Climate has international institutions, treaties, decades of science, and a maturing mitigation toolkit. They are insufficient, but they exist and they are real. AI safeguards exist (the Seoul frontier AI commitments,18UK Government, Frontier AI Safety Commitments, AI Seoul Summit 2024. Read. voluntary safety reporting, the AI Safety Institutes19UK AI Security Institute (formerly AI Safety Institute). aisi.gov.uk.) but they are early-stage, uneven and largely voluntary.
Conclusion Climate has stronger institutional safeguards, even if they are underperforming.
11 Epistemic confidence
Climate has high confidence in mechanism and direction, lower confidence on exact tail outcomes. AI has low-to-moderate confidence on mechanism, timeline and probability, but high enough concern to motivate international scientific assessment.
Conclusion Climate has far stronger epistemic footing.
The verdict, in one table
| Criterion | Climate change | AI misalignment |
|---|---|---|
| Severity ceiling | Very high | Potentially extreme; existentially higher |
| Probability of major harm | Higher But lower potential for ultimately existential harm |
Lower confidence But higher potential for ultimately existential harm |
| Time horizon | Already underway | Could be near-term |
| Velocity & warning time | Longer | Potentially very short |
| Detectability | Strong | Weak |
| Tractability | Hard but legible | Hard and unsettled |
| Reversibility | Partly irreversible | Potentially irreversible in a stronger sense |
| Exposure | Universal | Potentially universal, though more limited mechanisms |
| Safeguards | More mature | Nascent |
| Misuse interaction | Lower | Significantly higher |
| Epistemic confidence | High | Much lower |
So which is the gravest danger? Honestly, I do not think the answer is clean. Some criteria make climate worse. Some make AI worse. Reasonable people will weight them differently and come with different reasonable conclusions.
The cleanest summary I can offer is this.
Climate change is the stronger known and measurable planetary risk. AI misalignment is the stronger uncertain-but-potentially-dominant existential risk.
If you are deciding where to allocate attention under uncertainty, the right answer is not to pick one. It is to treat climate change as the urgent certainty, and AI misalignment as the high-upside prevention bet against the worst irreversible tail outcome.
07 / 09 · VII. The Asymmetry
So why are we acting on only one of them?
Here is the part that I find genuinely difficult to accept.
For climate change, we have the IPCC, the Intergovernmental Panel on Climate Change. We have decades of internationally coordinated science. We have COP summits, the Paris Agreement, national net-zero commitments, dedicated ministries, climate-disclosure regulations for listed companies, hundreds of billions of dollars flowing into mitigation and adaptation, an entire generation of climate scientists and activists, and a globally legible vocabulary that schoolchildren can use to discuss the problem. None of it is enough. But it is something, and it is enormous compared to what exists for AI.
For AI misalignment, what do we have?
A handful of nascent, often underfunded national AI Safety Institutes. A set of voluntary frontier safety commitments made at the Seoul and Bletchley Park summits.20UK Government, The Bletchley Declaration, AI Safety Summit 2023. Read. A growing but still fragmented international scientific report. A small community of alignment researchers who could, generously, fit in a single conference hall. No binding international treaty. No mandatory safety testing before deployment. We have early fragments of an international architecture, but nothing with the authority, continuity, scientific depth, or policy weight of the IPCC. No clear whistleblower protections for researchers inside frontier labs. Far less public funding for safety research than the labs are spending on capabilities, by orders of magnitude.
The asymmetry is staggering. We are spending a fraction of a fraction of a percent of the resources we devote to climate change on a risk that several Nobel laureates and frontier-lab CEOs say has comparable or higher tail severity, on a much shorter timeline, with much weaker epistemic tools to detect failure.
Whatever your take on the probability of AI catastrophe, the current allocation of attention and resources cannot be the right one.
08 / 09 · VIII. The Proposal
An IPCC for AI.

Which brings me to my recommendation.
We need an Intergovernmental Panel on Artificial Intelligence. An IPAI.
Modelled deliberately on the IPCC, because the IPCC, for all its flaws, is the single most successful institutional response humanity has ever built to a complex and consequential global risk. We should not start from scratch. We should steal what works.
What might it look like?
01
An independent international scientific body
Sponsored by the UN and constituted by national governments, with formal participation from every major AI-developing country. Not run by the labs. Not run by any single government. Insulated from commercial pressure the way the IPCC is insulated from oil companies.
02
A regular, rapid, authoritative assessment cycle
Perhaps every six months given the pace of the field, rather than the IPCC's six years. Synthesising the state of knowledge on AI capabilities, alignment research, deployment risks, misuse pathways and governance options. Drawing on thousands of researchers worldwide. Producing summaries for policymakers that translate technical evidence into language ministers and parliaments can actually act on.
03
A mandate to build shared scientific infrastructure
Standardised evaluations, open benchmarks for dangerous capabilities, common protocols for incident reporting, shared frameworks for what "frontier" actually means. Today, every lab uses its own definitions. This is untenable.
04
Strong protections for whistleblowers and dissenting researchers
Modelled on protections in nuclear, pharmaceutical and aviation safety. The people best placed to see misalignment first are the people with the most to lose by saying so. We need to change that dynamic.
05
A formal channel into international policy
The way IPCC reports feed into COP negotiations, so that scientific consensus actually shapes treaty-level decisions on capability thresholds, compute governance, deployment standards and red lines.
This will be hard. It will be politically messy. The major AI powers will resist anything that looks like binding constraint. The labs will lobby against anything that slows them down. There will be disagreement about scope, leadership, funding and authority. US versus China rivalry will be engaged.
The IPCC was hard too. It still got built. And imagine where we would be on climate if it didn't exist.
09 / 09 · IX. Where I Have Landed
Where I have landed.
I started this piece with a personal admission: that a year ago I realised I had been wrong about the timing of all this. I want to end with another one.
I do not know what the right answer is. I do not know whether AI misalignment will turn out to be the defining catastrophe of this century, a manageable risk we navigate successfully, or something we look back on in 2060 and realise we wildly overestimated. I genuinely do not know. Anyone who tells you they do is selling something.
But I do know this. We are running an experiment on ourselves, at speed, with tools whose inner workings we do not fully understand, with no agreed scientific method for verifying their alignment, with weak international coordination, and with the people closest to the technology telling us, on the record, with their reputations on the line, that the tail risks are real.
Under those conditions, the burden of proof should not lie with the people raising concerns. It should lie with the people saying everything is fine.
We built an IPCC for climate change because we understood that some risks are too large, too global and too consequential to leave to the goodwill of individual actors. That logic applies to AI now, with at least equal force.
Asimov's AC21In Asimov's story, AC stands for "Analog Computer", though as the story progresses through billions of years, it evolves through successive incarnations (Multivac, Galactic AC, Cosmic AC, Universal AC) until the final version, simply called AC, exists outside space and time entirely. took billions of years to answer humanity's last question, and by the time it did, there was no humanity left to hear it. We do not have billions of years. We may not have decades. The question we are now asking, can we build something vastly more capable than ourselves and remain in control of it, deserves an answer before it is too late to matter.
The fifteen-year-old who first read that story thought it was about the far future. It seems he was wrong about that too.
It is time to build the IPAI.